
NVIDIA was an early and aggressive advocate of leveraging graphics processors for other massively parallel processing tasks (often referred to as general-purpose computing on graphics processing units, or GPGPU). The company's CUDA software toolset for GPU computing has to date secured only modest success in mobile and desktop PCs; with game physics processing acceleration, for example, along with still and video image processing acceleration. However, GPGPU has been embraced in the HPC (high-performance computing) server space, and NVIDIA is the dominant supplier of GPUs for HPC. AMD acknowledges that it is behind, and the company's ROCm (Radeon Open Compute Platform) initiative, conceptually unveiled at last year's Supercomputing Conference and disclosed in a more fully implemented form at last month's SC16, is key to its planned catch-up (Figure 1).

Figure 1. First presented at the 2015 Supercomputing Conference, AMD's ROCm has come a long way in a year's time.
Historically, in contrast to NVIDIA's proprietary CUDA approach, AMD has elected to rely on industry-standard heterogeneous processing approaches such as OpenCL, along with the HSA Foundation's various efforts. But relying on standards has sometimes been a hindrance. For example, only with the late-2015 release of OpenCL v2.1 did the standard replace the legacy OpenCL C kernel language with OpenCL C++ (a subset of C++14), and then only in a provisional fashion. The OpenCL C++ kernel language will be fully integrated into the core specification with OpenCL v2.2 (now under development). In contrast, CUDA has supported programmer-friendly C++ since its mid-2007 initial release. Also, to date the HSA Foundation's specifications focus on graphics cores implemented alongside processor cores on unified SoCs such as in AMD's APUs (accelerated processing units). Perhaps obviously, servers require support for standalone graphics chips and boards, which is why (as InsideDSP's recent HSA coverage noted) ROCm expands beyond HSA standards in a proprietary fashion.
According to Gregory Stoner, AMD's Senior Director for Radeon Open Compute, ROCm (previously known by its "Boltzmann Initiative" project name), comprises a collection of technologies for efficiently harnessing GPU coprocessors (Figure 2). First is its OpenCL support, which Stoner describes as "OpenCL 1.2+" in its current form; based on an OpenCL v1.2 compatible runtime, along with a select subset of the OpenCL 2.0 kernel language enhancements. This mix may seem curious, given that OpenCL v1.2 dates back to 2011, but it's a pragmatic "nod" to competitor NVIDIA's current dominance in the HPC space, along with NVIDIA's reluctance to embrace anything beyond OpenCL v1.2.
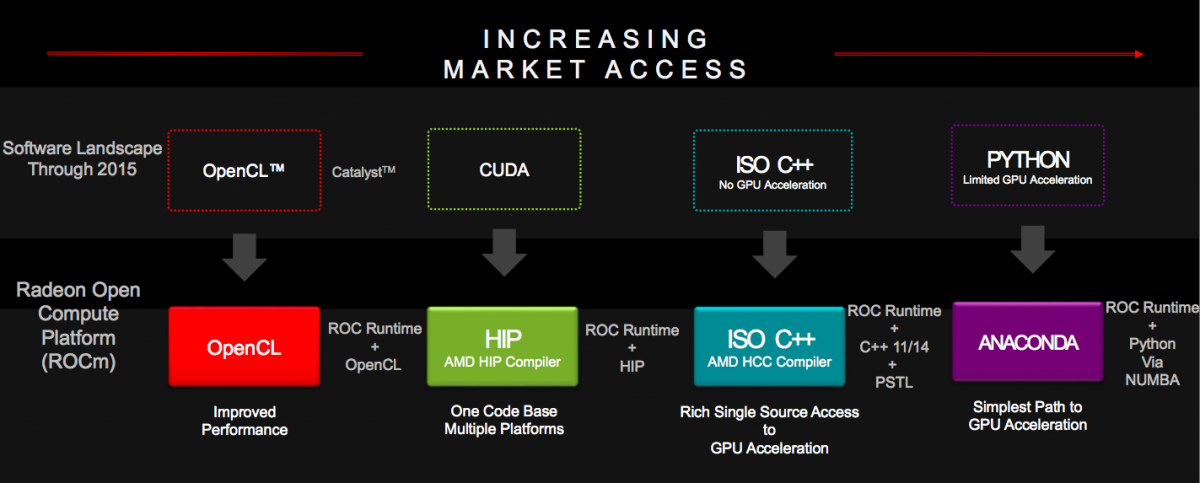
Figure 2. ROCm's various software tools and partnerships span the support spectrum from assembly language through Python, and are intended to address various developers' needs.
NVIDIA's (and CUDA's) present supremacy directly leads to another aspect of AMD's toolset: HIP (the Heterogeneous-compute Interface for Portability). A series of published HIP APIs allow developers to program for AMD GPUs in a CUDA-like schema. And the HIPify toolset enables developers to convert existing CUDA source code to a HIP-compatible equivalent, which according to Stoner also remains CUDA-compatible. When pressed about the legal ramifications of such a tool, Stoner pointed to the recent Oracle-vs-Google Java trial, which he claimed clarified the fair use of published APIs. Of course, AMD will bear the burden of keeping its toolset up to date as CUDA and its associated APIs continue to evolve.
As an example of HIPify's effectiveness, Stoner described a recent internal AMD project to port the GPU-accelerated, CUDA-based variant of the popular Caffe deep learning framework (Figure 3). According to Stoner, the currently published version of CUDA-accelerated Caffe contains more than 55,000 lines of source code. A fully manual port of the framework to an OpenCL-equivalent version, initially undertaken by the company, required modification of more than half of that source code and took approximately a developer half-year. Conversely, by leveraging HIPify, 99.6% of the source code was either unmodified or automatically converted (600 lines' worth), leaving only 300 lines of source code that still required manual intervention. The completed HIPify-assisted port required less than one week of developer time and supports all Caffe features; multi-GPU, peer-to-peer, FFT filters, etc. Plus, according to AMD, it runs 80% faster than the previous manually converted OpenCL version.

Figure 3. A HIPify utility-assisted port of the CUDA-based Caffe deep learning framework took less than a week and was nearly 100% automated, according to AMD.
The other key aspect of ROCm is its source code compiler, HCC (the Heterogeneous Compute Compiler). Clang- and LLVM-based, and leveraging some aspects of HSA, HCC aspires to be a unified C/C++/OpenMP compiler for both CPUs and GPUs (Figure 4). Parallelism is exposed several ways: via explicit syntax, for example, as well as by leveraging already-parallelized library functions. Recent enhancements include support for the 16-bit integer and floating-point operations supported in latest-generation AMD GPUs' ALUs. In situations when lower precision is acceptable, leverage of native 16-bit support decreases register and memory resource usage, as well as reducing code size due to the elimination of now-unnecessary 16-32 bit bidirectional conversions. Seemingly not yet enabled in the compiler, however, is support for the packed 16-bit formats supported in the latest-generation AMD GPU architecture found, for example, in Sony's PlayStation 4 Pro game console. Such support, if and when it arrives, will enable each 32-bit ALU to parallel-process up to two 16-bit instructions at the same time.

Figure 4. AMD's HCC unified compiler operates on a single source file, generating code for both the CPU and GPU.
Finally, AMD is addressing GPU-accelerated Python support via a partnership with Continuum Analytics, a primary supporter of the Numba toolset. Specifically, AMD is leveraging Continuum Analytics' Anaconda open-source data science software package set. Going forward, AMD will further improve both HCC and HIP, along with the company's OpenCL capabilities, among other ways by supporting newer generations of both CPUs and GPUs. Additionally, the company intends to further build out both internal and third-party library support; planned core math library examples, for example, include BLAS, SGEMM and DGEMM, FFT, SPARSE, RAND, and OpenVX.
While ROCm addresses AMD's customers' HPC and other heterogeneous processing needs in a general sense, deep learning training and inference acceleration support was not particularly emphasized in last month's announcements. However, as this article was being finalized, AMD released preliminary information on three new hardware acceleration boards for deep learning applications, along with deep learning library called MIOpen, which is conceptually similar to NVIDIA's cuDNN albeit being open source in AMD's case. Stay tuned for more details on both aspects of this latest news in a future edition of InsideDSP.
Add new comment