
Technology advances ever onward over time, and in fact its pace has accelerated since Jack Kilby's initial integrated circuit demonstration in 1958. So it is that, while CEVA's DSP core licensees are demonstrating SoCs based on the company's current-generation CEVA-XC323 (see "Picochip and Mindspeed: Former Competitors Unite to Address Wireless Spectrum Needs" in this issue of InsideDSP), CEVA is simultaneously unveiling its next-generation core, the XC4000 (Figure 1).
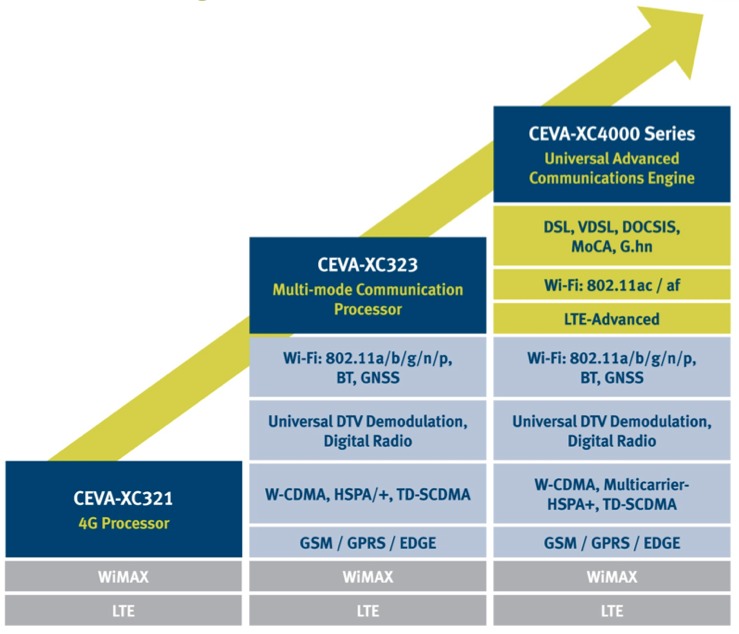
Figure 1. CEVA builds on the foundation of its first two generations of communications-tailored DSP cores, focusing on the latest standards with its new XC4000 family.
Make that the flexible, scalable XC4000 core family, available to lead licensees this quarter with general availability slated for Q2 (Figure 2). Whereas last month's InsideDSP edition described the company's investment in the emerging area of embedded vision (see "The CEVA-MM3101: An Imaging-Optimized DSP Core Swings for an Embedded Vision Home Run"), the XC4000 represents a focus on CEVA's foundation communications business. But while CEVA’s earlier communications-focused DSP offerings were individual cores, this time CEVA has simultaneously launched a suite of six related cores, containing largely common elements but in various counts and combinations targeting specific applications' needs.
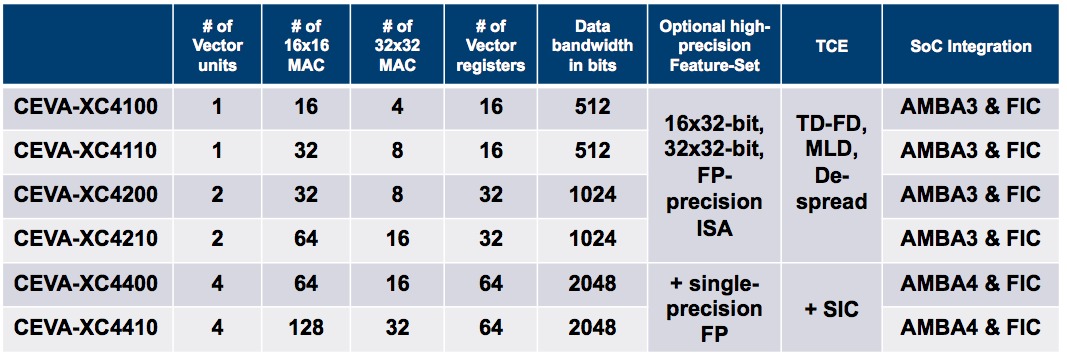
Figure 2. CEVA-XC4000 family members vary the number of vector units and registers, MACs and other on-core resources.
Eyal Bergman, the company's director of product marketing, refers to the XC4000 as a "Universal Communication Engine", i.e. CEVA's latest implementation of the software-defined radio vision. In rationalizing the need for such protocol flexibility, he points to the same exploding data-usage trends (which affect wireline and wireless networks alike) that I alluded to in this month's other InsideDSP feature article. Just last week, for example, Cisco published the latest edition of its Visual Networking Index report specifically covering mobile networks. The analysis contained the following eye-popping summary trends:
- Global mobile data traffic grew 2.3-fold in 2011, more than doubling for the fourth year in a row.
- Last year's mobile data traffic was eight times the size of the entire global Internet in 2000.
- Mobile video traffic exceeded 50 percent for the first time in 2011.
- Mobile network connection speeds grew 66 percent in 2011.
- In 2011, a fourth-generation (4G) connection generated 28 times more traffic on average than a non-4G connection. Although 4G connections represent only 0.2 percent of mobile connections today, they already account for 6 percent of mobile data traffic.
- The top 1 percent of mobile data subscribers generate 24 percent of mobile data traffic, down from 35 percent 1 year ago.
- Average smartphone usage nearly tripled in 2011. The average amount of traffic per smartphone in 2011 was 150 MB per month, up from 55 MB per month in 2010.
- Smartphones represent only 12 percent of total global handsets in use today, but they represent over 82 percent of total global handset traffic.
- Globally, 33 percent of handset and tablet traffic was offloaded onto the fixed network through dual-mode or femtocell in 2011.
- In 2011, the number of mobile-connected tablets tripled to 34 million, and each tablet generated 3.4 times more traffic than the average smartphone, and
- There were 175 million laptops on the mobile network in 2011, and each laptop generated 22 times more traffic than the average smartphone.
The Cisco report also provided the following near-future predictions:
- Monthly global mobile data traffic will surpass 10 exabytes in 2016. Over 100 million smartphone users will belong to the "gigabyte club" (over 1 GB per month) by 2012.
- The number of mobile-connected devices will exceed the world's population in 2012.
- The average mobile connection speed will surpass 1 Mbps in 2014.
- Due to increased usage on smartphones, handsets will exceed 50 percent of mobile data traffic in 2014.
- Monthly global mobile data traffic will surpass 10 exabytes in 2016.
- Monthly mobile tablet traffic will surpass 1 exabyte per month in 2016, and
- Tablets will exceed 10 percent of global mobile data traffic in 2016.
In order for many of these bandwidth-fueled predictions to pan out, network clients will need to support multiple topologies (not only cellular data, for example, but also multiple Wi-Fi flavors, along with "white spaces"), intelligently selecting among them as well as in some cases simultaneously leveraging multiple of them in order to optimize bandwidth, latency and other parameters. And both the clients and the network infrastructure equipment they're connected to (and to each other through) will need to be easily and robustly upgradeable to support both new standards and new iterations of existing standards.
In building on the XC323 foundation, CEVA began by making two particular power consumption optimizations (Figure 3). A second-generation PSU (power scaling unit) implements fine-grained clock and voltage management techniques that optimize both dynamic and leakage power and focus not only on the processing cores themselves but also on the internal and SoC-interconnect buses, on-chip memories, and the TCEs (tightly coupled extensions). And a power consumption-optimized pipeline delivers improved low-level module isolation, along with better vector element utilization via MAC scalability (i.e. the ability for each MAC structure to implement 16x16, 16x32 or 32x32 arithmetic).
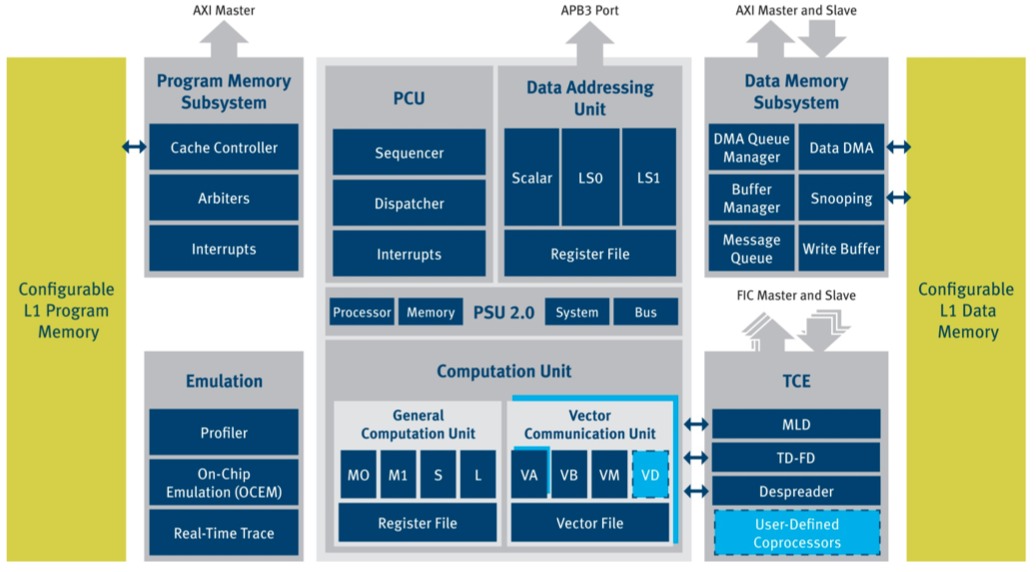
Figure 3. Function-specific coprocessors which CEVA calls TCEs (tightly coupled extensions) are key to the cores' performance, power consumption and silicon efficiency improvements versus precursors, and can be supplemented by licensees' custom logic blocks.
The TCEs are function-tailored, hardware-accelerated coprocessors. They are a key part of the reason why CEVA claims that an XC4000-based LTE-Advanced PHY will be more than 50% smaller than its CEVA-XC323-implemented predecessor even when fabricated in the same process. Specifically, CEVA claims that the CEVA-XC4000-based LTE-A PHY on TSMC's 28 nm process will be only 3.4 mm2 in size and will consume only 100 mW. Similarly, an IEEE 802.11ac reference architecture that CEVA developed in partnership with Antcor addresses both the PHY and lower-MAC functions, consumes as little as 16 mW for 30 Mbps bandwidth (sufficient, CEVA claims, for robust Blu-ray multimedia streaming), and takes up as little as 1.5 mm2 of silicon area in TSMC's 28 nm process, according to CEVA.
Three TCEs are found in all members of the XC4000 family:
- A programmable MLD (maximum likelihood decoder) for MIMO antenna configurations
- A flexible time-frequency domain converter, and a
- Programmable descrambler/despreader addressing various 3G cellular standards
Note that the TCEs direct-connect to the X4000's computation unit and also interface to the remainder of the core over a high-speed, low-latency proprietary FIC (fast interconnect) bus with a user-configurable number of master/slave ports and up to 1.5 Tbps peak transfer speeds over a 1,024-bit maximum bus width. The FIC ports supplement the AMBA3-standardizes AXI interconnect found in both this and prior-generation CEVA cores. The XC4000 architecture also allows for licensee-defined co-processors in the TCE area, and the two high-end members of the XC4000 family add a fourth CEVA-developed TCE implementing advanced AMBA4 system interconnect.
Bigger picture, the six XC4000 family members vary the numbers of included vector units and registers (up to 64, either 256- or 320-bit wide), as well as the number of scalable MACs and the resultant aggregate on-core data bus width. Bergman believes that only infrastructure applications demand single-precision floating-point capabilities, which is why you'll only find IEEE-standard support for them on the high-end XC4400 and XC4410. Conversely, the fixed-point arithmetic instruction set found in all six core variants supports 16x16 (at up to 128 concurrent MACs), 16x32 and 32x32 bit arithmetic, with 40-bit mantissa and 72-bit accumulation support that can surpass standard floating point precision where necessary, all leading to claimed sub-0.3 dB signal loss through an entire modem receiver chain, along with notably lower power consumption than in a "true" floating point algorithm implementation.
The CEVA-XC4000 family's support for more than 250 new communication-specific instructions, along with its unrestricted 8-way VLIW architecture that allows any combination of units to be parallelized, translates into up to 5x higher performance than CEVA-XC323 according to the company. Specifically, CEVA has added a MIMO instruction set intended for QR and Cholesky matrix decomposition, along with advanced mechanisms tailored for maximum likelihood determination in high MIMO dimensions. More generally, the cores' complex mathematics capabilities enable them to tackle up to 32 division, square root, and inverse square operations per cycle.
While some SoC developers continue to leverage "hard-wired" modem cores in their designs, the increasing complexity and evolutionary pace of communications standards will make this legacy design approach increasingly untenable over time. With the XC4000 series, CEVA is well positioned to supply both existing and new licensees with software-defined radio successors that comprehend both latest-generation and coming-soon protocols.
Add new comment