
Audio processing functions are usually implemented in software (rather than fixed-function hardware) because software provides flexibility that is not available with hard-wired solutions. For example, compressed audio players are typically required to support a variety of different algorithms such as MPEG-1/Layer 3 (MP3), Windows Media Audio (WMA), and MPEG-AAC. As algorithms evolve, and as new algorithms are introduced, designers of software-based products can upgrade their devices. In this article we tackle audio software-development issues, sharing some of the hard-learned lessons from our many years of experience developing software for consumer and professional audio gear.
Developing audio software is challenging for several reasons. One major source of challenges is the human auditory system. Table 1 shows some of the special attributes of the human auditory system and the corresponding ramifications for audio system design.
The demanding nature of the human auditory system means that testing is a critical step in audio software development. Adding to the challenges faced by software developers, audio products typically have very constrained hardware resources. In larger systems, like video games, audio functions are typically given a small percentage (sometimes 5% or less) of the overall processing budget. To keep prices low, audio-only devices typically use inexpensive processors (such as relatively slow 8- or 16-bit processors), and include modest memory (in terms of both size and bandwidth). Implementing complex audio processing algorithms on relatively limited hardware requires careful software optimization. In this article, we'll focus on challenges and techniques in audio software optimization and testing, using a reverb algorithm as a case study.

Development Example: Reverb
“Reverb,” short for reverberation, is the complicated set of reflections that are produced when a sound travels from a source to a listener by bouncing off many different surfaces. These reflections provide important cues to our brains—for example, allowing us to distinguish whether we are in a small bathroom or a large stadium. To enhance the listening experience, audio products ranging from professional recording studio equipment to consumer home-theatre receivers incorporate reverb algorithms to simulate the reflections of particular listening spaces.
For our design example, we'll use a Schroeder reverb algorithm, illustrated in Figure 1. A Schroeder reverb is representative of many reverb algorithms in that it uses a combination of allpass filters and comb filters. The reverb's reflections are generated by recirculating and attenuating the input signal through the recursive filter structures.

Optimization
Audio software optimization is the process of reducing the hardware resources required by the software while maintaining sufficient audio quality. When output audio samples are not produced quickly enough, the product's hard real-time constraints are not met and audible, annoying artifacts (such as clicks and pops) result. Therefore, audio software developers initially focus is on reducing the computational load to ensure samples are produced in a timely manner.
Optimizing for memory space comes second; although it is important because it reduces the system cost, it is less critical than meeting real-time constraints. There is typically a tradeoff between speed and size—reducing the computational load often increases the memory requirements. For example, instead of calculating parameters in real time, it may be faster to look up the required values using a pre-calculated table that consumes memory space.
The first step in optimization is to analyze the code to find the routines with the highest processor load and then improve them one by one. The processing rates for audio software routines can typically be separated into three categories, sometimes called I-rate, K-rate, and S-rate. I-rate routines run infrequently, typically at power-up or for a mode change. K-rate routines run more frequently and are often the user interface and control functions. S-rate routines run the most frequently and usually generate the actual audio output samples. S-rate routines use the lion's share of the processor's time, so they should be optimized first.
There are many methods for reducing the computational load of audio software routines. High-level optimizations include techniques such as substituting one algorithm for another or processing blocks of samples at a time instead of a single sample at a time. Lower-level optimizations include manually selecting and scheduling instructions for key inner loops, and employing specialized processor hardware features like DMA.
Reducing Memory Size and Bandwidth Needs
Reverb algorithms typically use more data memory (32 kB to 128 kB or more), in the form of delay lines, than other audio post-processing effects. Delay lines, which are implemented using a contiguous chunk of memory, are a common building block for audio effects and are used to delay a signal by a specific amount of time. One way to implement a delay line is to use a first-in, first-out (FIFO) buffer implemented using circular buffering. A write pointer points to the location in memory where the next input sample is to be written into the delay line, and a read pointer points to the next sample to be read from the delay line. The number of samples between the two pointers defines the delay time. When either of the pointers reaches the end of the buffer, it "wraps around" to the beginning. Accessing memory is a common bottleneck, so optimizations that reduce the number of memory accesses and take advantage of specialized memory accessing hardware can produce good results.
Reducing the amount of memory required is one motivation for choosing an alternative algorithm. The idea is to find a different algorithm that produces nearly the same output while using less memory. Reverb algorithms have been an area of active research for many years, so the literature is filled with options. In place of the Schroeder reverb we might use an alternative algorithm that requires less memory and makes fewer memory accesses. A few algorithms reduce the amount of data memory sufficiently so that it may be possible to place all of the delay lines in fast, on-chip memory, thereby nearly eliminating memory-access bottlenecks. But the subjective nature of perceived audio quality means that caution is advised: unless the memory reduced algorithm is properly designed, it won't sound very good.
Low-Level Optimizations
Once the algorithm has been selected and compiled for the chosen processor, it's time to consider lower-level optimizations. Because compilers often have difficulty generating optimal instruction sequences for signal processing algorithms, rewriting key inner loops in assembly language—or tweaking the assembly language code generated by the compiler—can yield big gains.
Working at the assembly language level requires a detailed knowledge of the processor's instruction set, pipeline, and memory architecture. Armed with this knowledge, the software developer can often improve on the performance of compiled code by using specialized instructions that the compiler ignores. For example, many processors today support single-instruction, multiple-data (SIMD) instructions that perform multiple operations of the same type (such as two additions) in parallel. Compilers rarely utilize such instructions, but a skilled programmer can often find ways to use the added parallelism to get big gains in performance. Achieving really tight code means not only selecting the best instructions, but also sequencing (or "scheduling") them for fastest execution. Virtually every processor today uses a pipeline; with a pipelined processor, often the result of an instruction isn't available until several cycles after that instruction executes. As a result, if an instruction uses a value produced by a preceding instruction, a pipeline stall often occurs. The way around this is to manually rearrange the instruction sequence so that operations from different parts of the algorithm are interleaved in a manner that avoids pipeline hazards without changing the functionality of the code. For example, after issuing a memory load instruction, while waiting for the data to become available, it is often possible to calculate a filter output using data previously loaded from memory. Instruction scheduling optimizations are not always obvious and require an in-depth knowledge of the processor's architecture.
Sometimes compilers can be cajoled into selecting the optimal instructions and scheduling them perfectly, but this often requires permuting the high-level language code in complex ways. It's often easier just to rewrite the key S-rate inner loops in assembly language. Of course, optimizations that involve writing assembly code make software less portable to other processors.
Memory Addressing Tweaks
Audio signal processing algorithms tend to access data memory frequently, sometimes using complex addressing patterns. As a result, optimizations that streamline memory accesses can pay big dividends. Many DSPs have specialized addressing modes useful for audio algorithms—but utilizing those modes typically requires working in assembly language and spending some quality time with the processor documentation.
For example, many processors support an addressing mode where an address register is automatically incremented by an offset value, as part of a memory load operation. This incrementing can take place either before or after the address is used for the current load operation. Typically, updating the address before the load consumes one extra processor cycle compared to updating it after the load.
On some processors, this auto-increment feature can increment address registers by a simple fixed amount, such as +1 or -1, or by a value held in another register. This feature works well with many audio algorithms, but often doesn't work well for reverbs, because reverbs usually don't access memory with a fixed stride. This means we usually prefer a memory addressing option that does not automatically modify the base address; instead, we prefer an addressing mode that allows an arbitrary offset to be combined efficiently with the base address to form an effective address, without updating the base address register.
Earlier we mentioned the use of circular buffers for delay lines. Implementing circular buffers requires the use of modulo arithmetic when incrementing address pointers, so that when the address pointers are incremented, they stay within the bounds of the buffer. Some processors provide hardware support for this type of modulo address arithmetic, making it possible to implement circular buffers very efficiently.
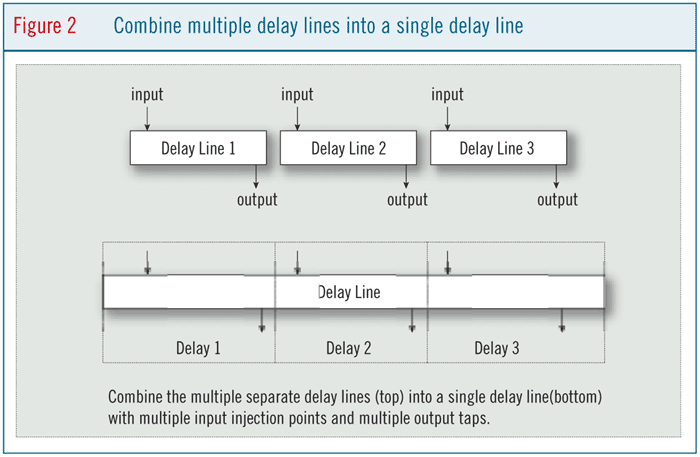
Returning to our reverb example, if the reverb algorithm uses many delay lines, a further memory-related optimization is possible. Instead of having multiple, separate delay lines, it may be more efficient to aggregate all of the delay lines into a single delay line with multiple read and write pointers, as shown in Figure 2. Combining the delay lines this way reduces the cost of initializing the circular buffer hardware, since only one set of circular buffer boundaries needs to be defined.
Testing
Thorough testing of an audio product helps ensure that the product not only meets its quantitative specifications but that it also sounds good. Audio software testing challenges include creating a suitable test environment, developing meaningful test vectors, performing static and dynamic tests, and taking objective and subjective measurements.
Creating a Test Environment
Finding a suitable test environment requires thinking not only about the tools (such as the debugger and development board), but also the physical listening environment. For example, multi-channel audio systems, which are commonly found in home theater receivers, are difficult to test because real time hardware that handles multi-channel inputs and outputs is not readily available. It may be impossible to perform real-time software tests before the product prototype hardware is ready because development boards from processor vendors, such as evaluation modules, often have only stereo inputs and outputs at best.
For the listening environment, testing can often be conducted using headphones for stereo algorithms, including most decompression algorithms. However, multi-channel algorithms are played back using more than just two speakers and require a quiet listening environment. Depending on the product's target market and specifications, it may be necessary to have a separate, acoustically treated "sound room" for testing and evaluation.
"Golden Ears"
Testing challenges also vary depending on the type of algorithms used in the system. Testing reverb algorithms, for example, is different from testing audio decompression algorithms. With audio decompression algorithms, typically the algorithm provider supplies a reference implementation of the algorithm along with test vectors, simplifying the task of checking whether your implementation functions correctly.
With other kinds of algorithms, like reverb, off-the-shelf reference test infrastructure is rarely available. And evaluating reverb sound quality often requires subjective testing by an expert listener, who usually isn't the person writing the software. This type of testing is far more difficult than just listening to music. Critical listening is not a passive form of entertainment; it is demanding and difficult to do for extended periods of time. Finally, thoroughly testing a multi-channel reverb is time consuming because there can be many configurations of inputs (1 to 6 channels), outputs (1 to 6 channels), operating modes, and parameters—each of which must be tested.
Static and Dynamic Tests
Whether performing objective or subjective testing, it is usually necessary to employ both static and dynamic tests, illustrated in Figure 3. Static testing can be performed by feeding simple inputs such as impulses into the system and recording the responses to a file for offline analysis. Static tests are useful because they can validate the basic algorithm functionality and can run (not in real-time) on a processor simulator instead of actual hardware. For example, in testing a reverb it is useful to apply a single impulse individually to each input and ensure that the impulse travels through each delay line as expected. Offline analysis should include certain objective measurements like Rt60, which is a basic reverb parameter that measures the amount of time required for the reverb response to decay by 60 dB. This type of measurement usually requires developing custom analysis software and having a good knowledge of reverb algorithms.

Like many audio algorithms, sophisticated reverb algorithms have time-varying parameters such as delay-line tap weights and positions that change with time. (A tap weight is the multiplication coefficient applied to a delay line output. The tap position is the relative offset between the delay line's read and write pointers.) It is therefore important to test that taps stay within their delay-line boundaries, otherwise unwanted signals will be injected into the reverb, which will corrupt the delay lines, creating annoying noises and potentially causing the reverb to become unstable.
For a reverb, as for many audio algorithms, dynamic testing is necessary because it is important to listen to the algorithm using a variety of musical signals under real-time operating conditions. The reverb must sound good at all times, and should not produce any audible artifacts, such as noise, even when the user changes parameters rapidly. Despite the reverb designer's best efforts, it is nearly impossible to develop a good-sounding reverb without some degree of iterative fine-tuning. It may therefore be necessary to develop an interactive method of adjusting reverb parameters in real time, perhaps through a graphical user interface.
Developing a comprehensive set of test signals for real-time evaluation is difficult. A wide variety of signals should be applied because users will employ many different genres of music, program material, and input/output channel combinations. Testing the device with the developer's favorite music is usually not enough.
Conclusions
As increasingly sophisticated audio features are added to an expanding range of inexpensive consumer electronics products, optimization of audio software is one key to successful products. Developers must continue to find ways to deliver more functionality for less cost, which means minimizing the use of processing and memory resources. But even in this resource-constrained environment, good audio quality is important. And good audio quality can be achieved only with careful testing—testing that requires a combination of art and science, taking into account the complexities of the technology and the subtleties of the human auditory system.
This article was contributed to by Shree Paranjpe
Add new comment