
Emerging and evolving options for high-level design of FPGAs is a topic of ongoing interest at InsideDSP. Recently, for example, BDTI covered the latest version of Calypto's Catapult C-based design environment. Similarly, in August 2012 InsideDSP discussed the C-based high-level synthesis (HLS) facilities that Xilinx bundled in some versions of its Vivado FPGA design toolset. And less than a year ago, BDTI analyzed a different approach to high-level synthesis, based on the Khronos Group's OpenCL, implemented by Altera.
As InsideDSP said then:
OpenCL provides a means of developing, in a hardware-independent manner, code that can be easily partitioned among the various available processing platforms within a heterogeneous system...CPUs, GPUs, DSPs and (of course) FPGAs. For far more information, see BDTI Senior Engineer Shehrzad Qureshi's OpenCL presentation from the July 2012 Embedded Vision Alliance Member Meeting (registration on the Embedded Vision Alliance website is required prior to accessing the video).
OpenCL has been notably embraced by high-end servers and supercomputers, which are one application example of the use of GPUs for GPGPU (general-purpose computing on graphics processing units) applications. Over time, these systems have increasingly leveraged the massively parallel processing resources in GPUs via NVIDIA's CUDA development environment and (more recently) OpenCL. And OpenCL's momentum makes those same applications natural targets for other OpenCL-embracing companies such as Altera. To wit, BDTI wrote in its February 2013 coverage, "Altera's approach is oriented towards high-performance computing applications."
FPGAs, like GPUs, are a silicon platform with significant parallel processing potential (PDF). So it's no surprise that GPGPU applications such as servers are not only on Altera's radar screen but also on primary FPGA competitor Xilinx's. In engaging with potential server customers, explained Tom Feist (Xilinx Senior Director of Design Methodology Marketing) and Vinay Singh (Senior Product Marketing Manager) in a recent briefing, the company realized that it would need to expand beyond C-based high-level synthesis in order to effectively compete against both GPU and FPGA competitors. And the server applications that Xilinx is focusing on will be of interest to any digital signal-processing aficionado: image recognition and speech transcription, for example, along with oil and gas exploration and a range of defense and intelligence analysis applications.
The result of this insight is Xilinx's recently announced (appropriately at the Super Computing Conference) SDAccel toolset, which builds on the company's existing HLS foundation with an optimizing compiler that comprehends not only C and C++ but also OpenCL, and which currently focuses on x86 CPU-based systems with PCI Express interfaces to FPGA-based add-in cards (Figure 1). Just last week, in fact, Xilinx's compiler was deemed OpenCL 1.0 conformance-compliant by Khronos.
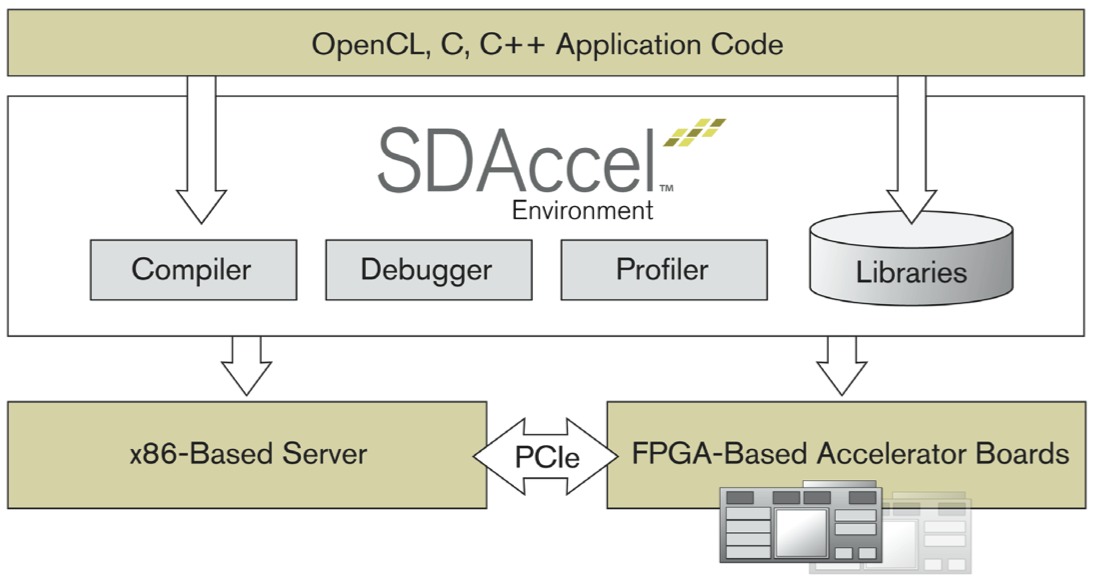
Xilinx's SDAccel development environment builds on the company's existing C HLS capabilities by supporting OpenCL, and targets digital signal processing-focused and other specific classes of servers and supercomputers.
In quantifying what Xilinx believes to be the fundamental performance/watt advantage of FPGAs in certain classes of server applications, Feist and Singh shared data presented by Chinese search engine company Baidu at the 2014 IEEE Hot Chips Conference, comparing the search algorithm acceleration capabilities of a sub-20W Xilinx Kintex-7 FPGA, an 80W Intel Xeon CPU, and a 225W NVIDIA K10 GPU across a range of parallel-thread scenarios (Figure 2). Specifically, according to Xilinx, Baidu found that a mid-range FPGA such as the Kintex-7 could deliver 375 GFLOPS of sustained performance while consuming between 10-20W of power, along with delivering significant latency improvements over CPUs.
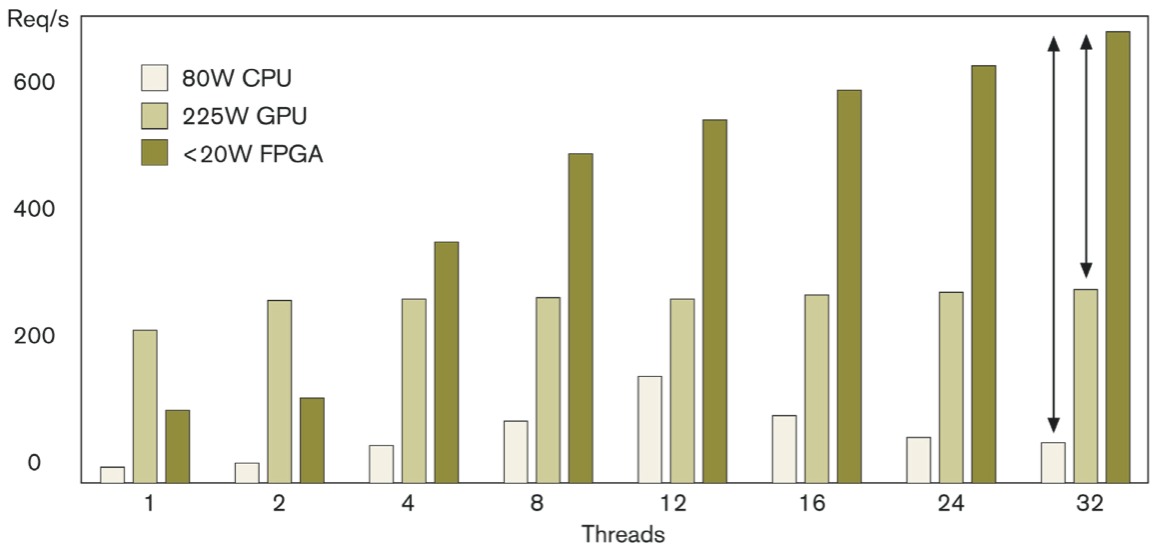
Figure 2. Baidu's analysis shows significant performance/watt benefit from running certain classes of predictive search algorithms on a FPGA versus on a CPU or GPU.
In comparing Xilinx's silicon-plus-development software suite combination against competitors' FPGA alternatives, Feist and Singh offered up more benchmark results that they said came from potential customers that have evaluated the company's offerings using unspecified "industry-standard" algorithms (Table 1). Given the small number of benchmarks offered, and their source, these results must be taken with a grain of salt. Nevertheless, they are intriguing in suggesting that Xilinx OpenCL methodology can deliver performance and area (resource use) results similar to that obtained from traditional Verilog or VHDL register-transfer-level (RTL) design. And, according to Xilinx, these OpenCL-based designs were developed in a fraction of the time that hand-coded RTL would have required.

Table 1. "Bakeoffs" by potential customers comparing multiple FPGA vendors' silicon-plus-toolset offerings, Xilinx claims, suggest OpenCL performance and efficiency comparable to hand-coded RTL, combined with a much shorter development schedule.
With respect to the architectural optimization capabilities of the SDAccel compiler, Feist and Singh provided a list of optimizations on which Xilinx focused its attention (Table 2). And the company is keen to make it clear that the SDAccel program isn't just a compiler and associated software tools; Xilinx has partnered with Alpha Data, Convey Computer and Pico Computing to provide compatible PCI Express add-in cards, and additionally offers optimized OpenCV computer vision and BLAS (Basic Linear Algebra Subprogram) functions developed by partner Auviz Systems.
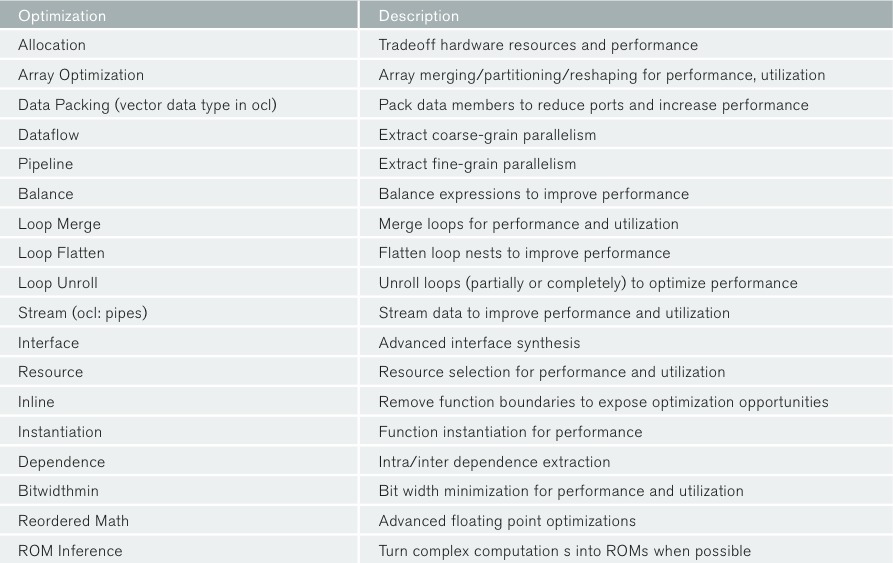
Table 2. Xilinx's optimizing compiler maps a range of common digital signal processing and other functions to the company's FPGAs architectures.
Of the three hardware board partners, only Alpha Data currently implements SDAccel's optional partial reconfiguration capability, due to the uniqueness of its PCI Express interface hardware implementation (Figure 3). And, as with the Altera OpenCL SDK that predated it, SDAccel makes specific assumptions as to the characteristics of the communication channel between the CPU and FPGA, and of the system memory that they share. It will be interesting to see how long it takes Xilinx to expand its OpenCL support to a wider range of system architectures, especially the company's Zynq-7000 ARM-plus-FPGA SoCs.
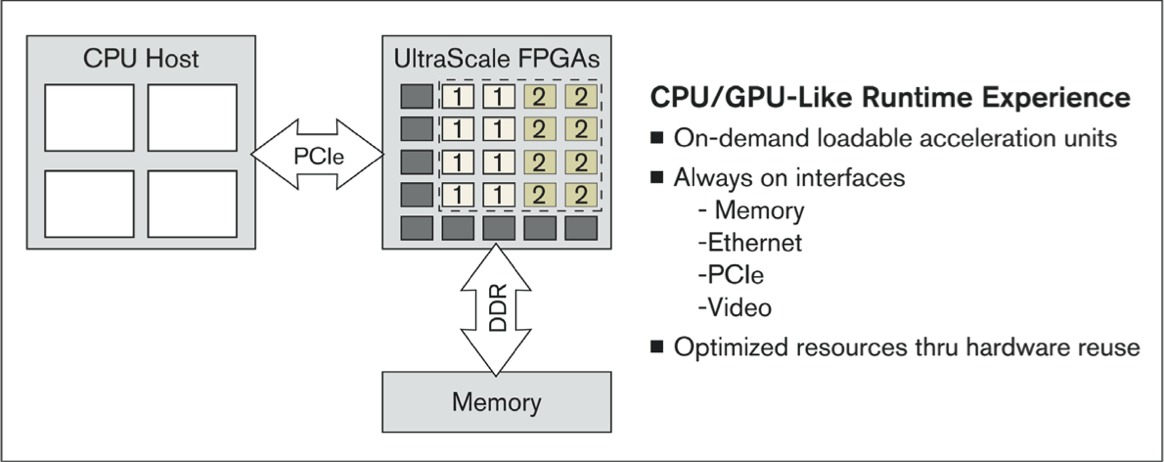
Figure 3. Partial reconfiguration support enables you, for example, to keep your PCI Express and memory interfaces intact while dynamically reprogramming other portions of the FPGA fabric to accelerate a particular task at hand, but isn't currently implemented by all of Xilinx’s SDAccel board partners.
It will also be interesting to observe Altera's response to Xilinx's entrance into the OpenCL-for-high-performance-computing space, which Altera has had to itself for some time. Although OpenCL is positioned as a silicon architecture-generic algorithm acceleration standard, it was developed first and foremost with GPUs in mind, implementing (for example) threading and memory models tailored for GPU architectures. OpenCL happens to also be a good fit for also implementing massively parallel algorithms on FPGAs, although in some cases this may require vendor-specific OpenCL extensions. But FPGAs' expanded fabric flexibility beyond GPUs opens the door to the implementation of classes of algorithms for which synthesis via other high-level languages techniques such as C may be more optimal. Xilinx obtained C HLS technology through its early 2011 acquisition of AutoESL, which the company integrated first in Vivado HLS and now in SDAccel. Will Altera sooner-or-later respond with its own C language-based synthesis support, and if so, how?
Add new comment