
The title of the press release for CEVA's latest XC-4500 communications DSP core, introduced in mid-October, claims that it's the "World's First Vector Floating-Point DSP for Wireless Infrastructure Solutions." Those of you with good memories might be confused at this point, in thinking back to InsideDSP's February 2012 coverage of CEVA's prior-generation XC-4000 family. To clarify, although the earlier XC-4400 and XC-4410 also offered IEEE 754-compliant floating-point support, it was not vectorized in that particular generation. And more generally, CEVA believes that the new XC-4500 is a better fit than its predecessors for a range of infrastructure equipment opportunities, from remote digital front-end radio heads through multi-mode baseband processing in various-sized base stations, and all the way to wireless backhaul equipment.
The XC-4500 core enhancements begin with a redesigned pipeline. Deeper, albeit with no notable claimed degradation in "miss" stalls as a result, it boosts the target clock rate by more than 15%, from 1.1 GHz (XC-4000) to 1.3 GHz (XC-4500) on an identical 28 nm process foundation. This speed increase yields an estimated 40 GFLOPs of peak floating-point calculation performance. Also, in comparing the XC-4500 block diagram to that of the XC-4000, you'll notice that this time CEVA added FHT (Fast Hadamard Transform), Viterbi and HARQ (Hybrid Automatic Repeat Request) hardware acceleration TCEs (tightly coupled extensions), all useful in various MIMO wireless implementations, for example (Figure 1).
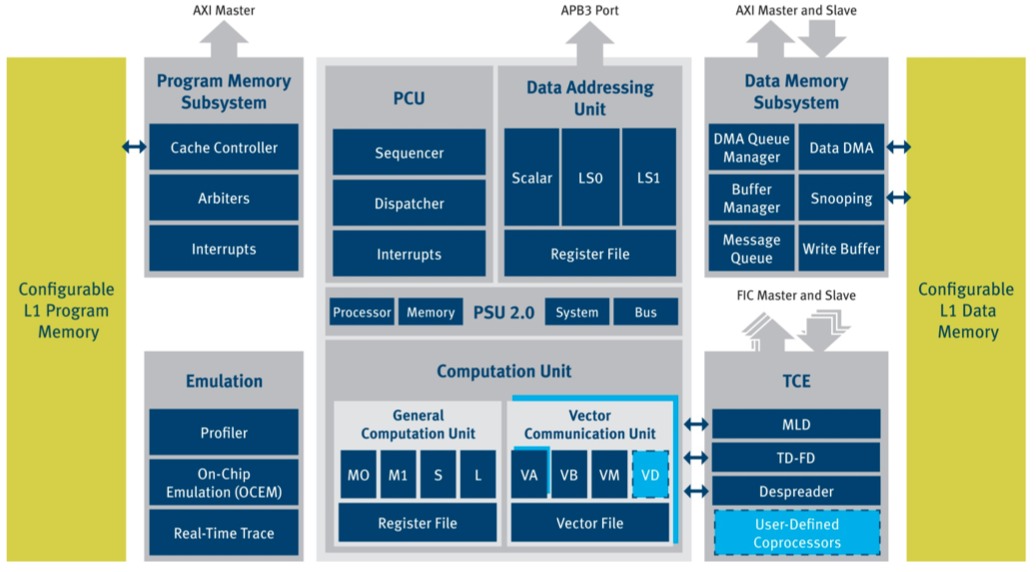
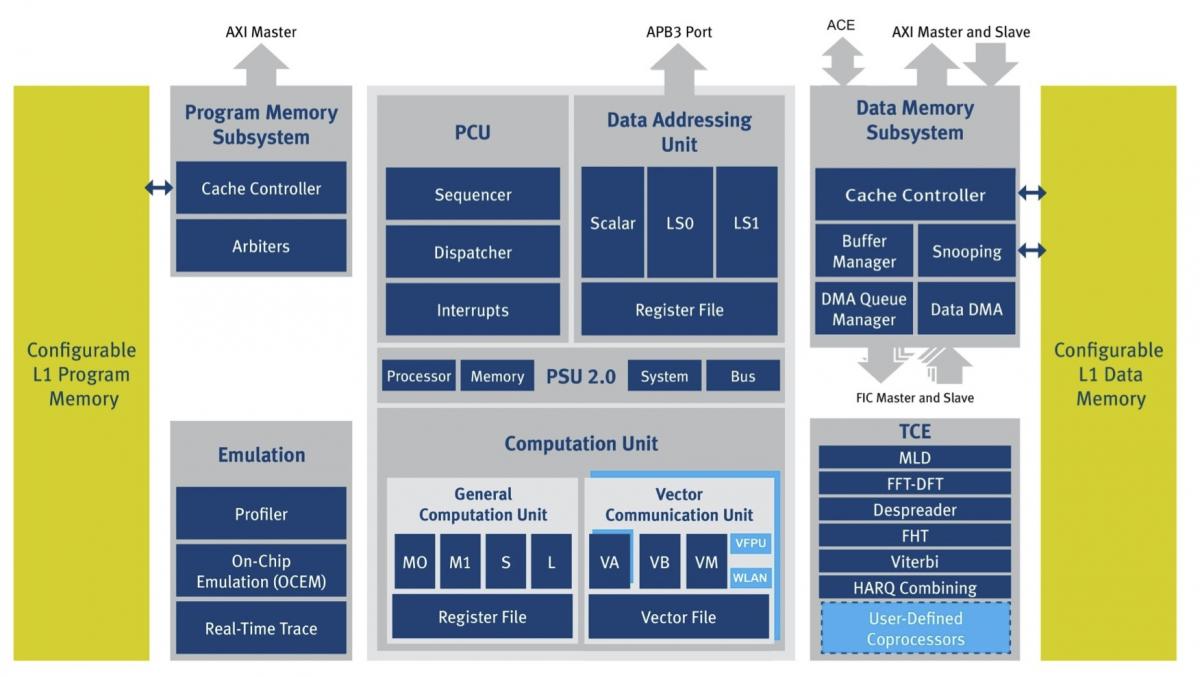
Figure 1. The evolution from the XC-4400 (top) to the XC-4500 (bottom) may seem minor to the eye, but CEVA feels that the enhancements are key to delivering multi-core infrastructure design wins.
Now come the multi-core implementation improvements. In a handset such as those where the XC-4210 has achieved success, Product Marketing Vice President Eyal Bergman explains, multi-processor configurations tend to be heterogeneous, containing various cores tailored for different purposes (Figure 2). Although these application-specific cores need to interact with each other to some degree, thereby explaining the ARM AMBA (Advanced Microcontroller Bus Architecture) v3 or (on the XC-4400 and XC-4410) v4 AXI (Advanced Extensible Interface) capabilities of the XC-4000 family, along with its CEVA-proprietary FIC (Fast Interconnect) support, tight coherency is comparatively unimportant. In infrastructure designs, on the other hand, traffic management (packet processing, effectively) is the key function being performed, and scalability is key in enabling a common software foundation to operate across a range of cellular base station (femtocell to macrocell) and other system hardware configurations.
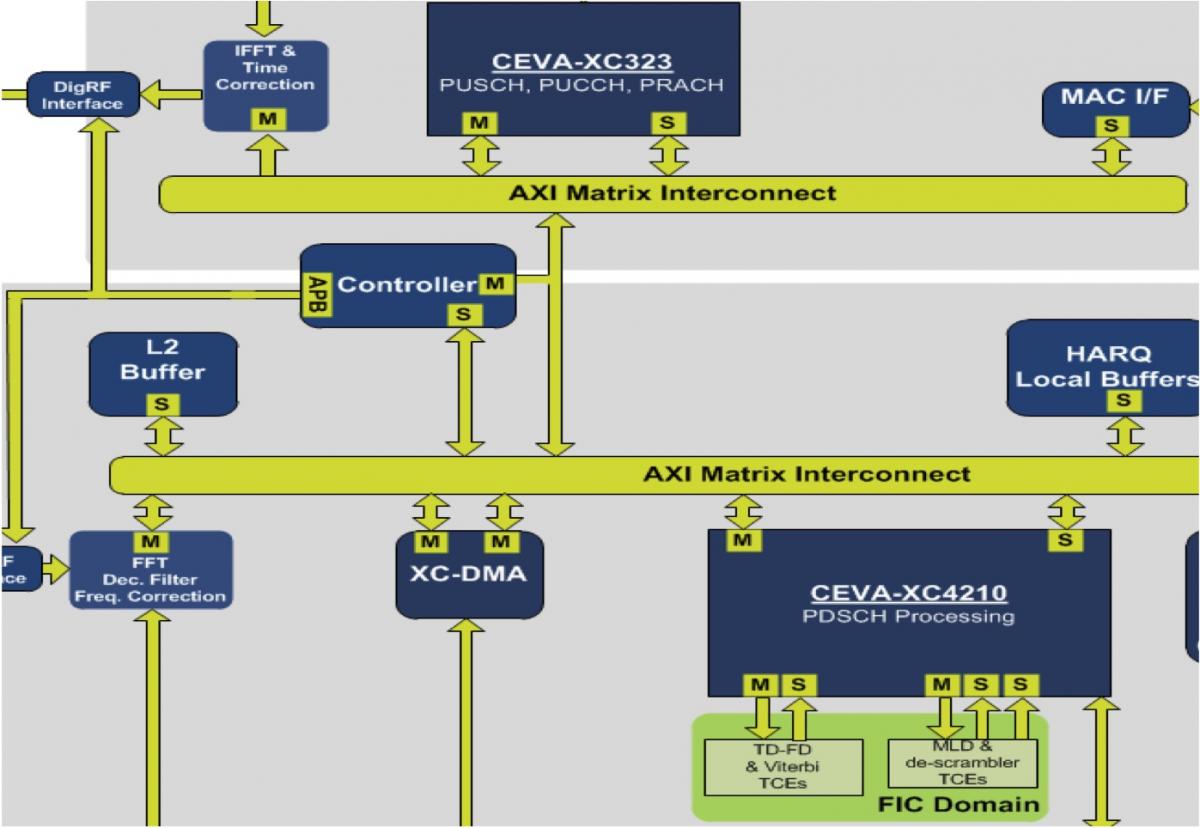
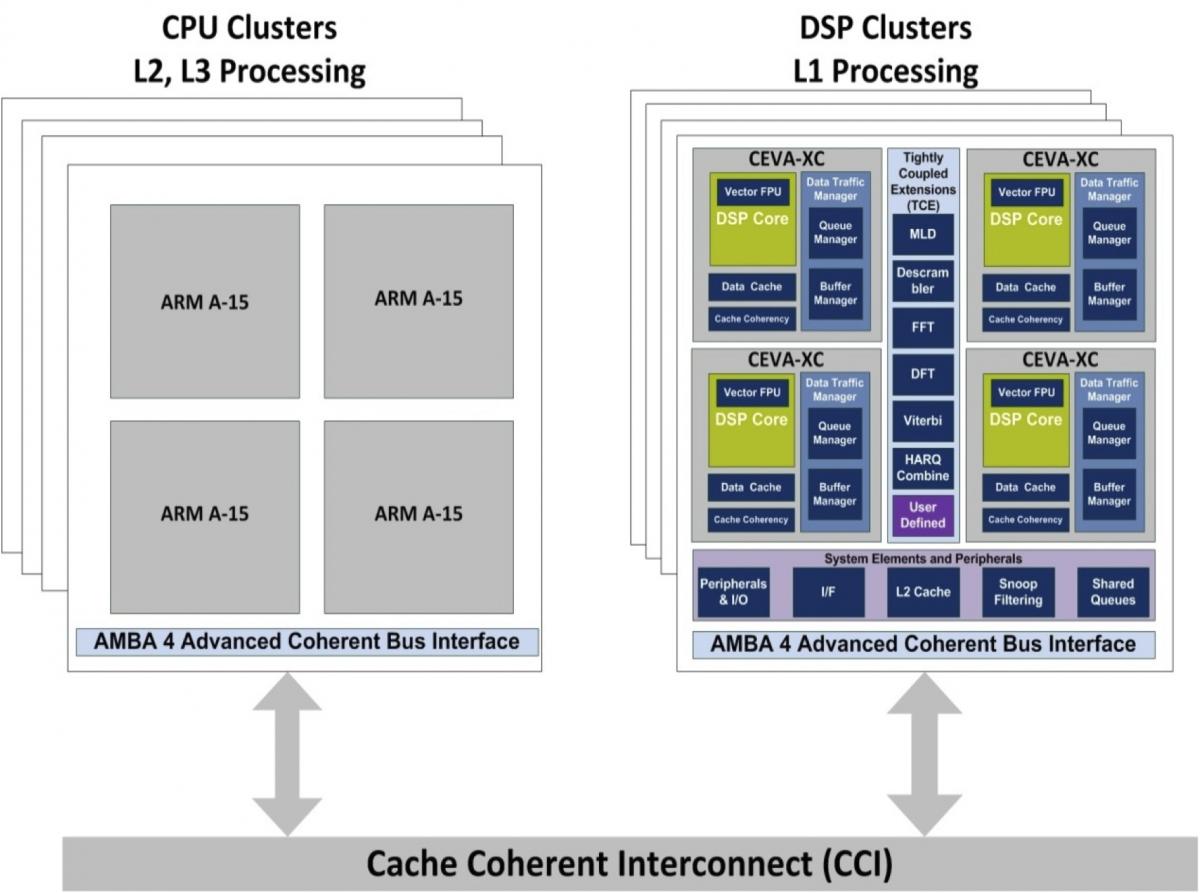
Figure 2. Whereas a wireless handset's heterogeneous architecture contains multiple loosely coupled processor cores each tailored for specific (and unique) functions (top), the homogeneous cores in an infrastructure system design must work in close coordination (bottom).
A homogeneous SMP (symmetric multi-processing) approach is therefore highly desirable in these application cases. Look closely again at the Figure 1 block diagrams, and you'll see how CEVA has addressed this need. The Data Memory Subsystem of the XC-4500 augments its precursor's support for AMBA4 AXI with explicit ACE (AXI Coherency Extensions) support. Not shown in Figure 1, but explicitly visible in the bigger-picture Figure 2 block diagram, is the corresponding L2 data cache, with non-blocking support and both write-back and write-through operation options. The L2 cache is shared by multiple XC-4500 DSP cores without software intervention, simplifying code development. And portions of it can optionally (and dynamically) be reserved as core-exclusive, wherein "snooping" is disabled (Figure 3).
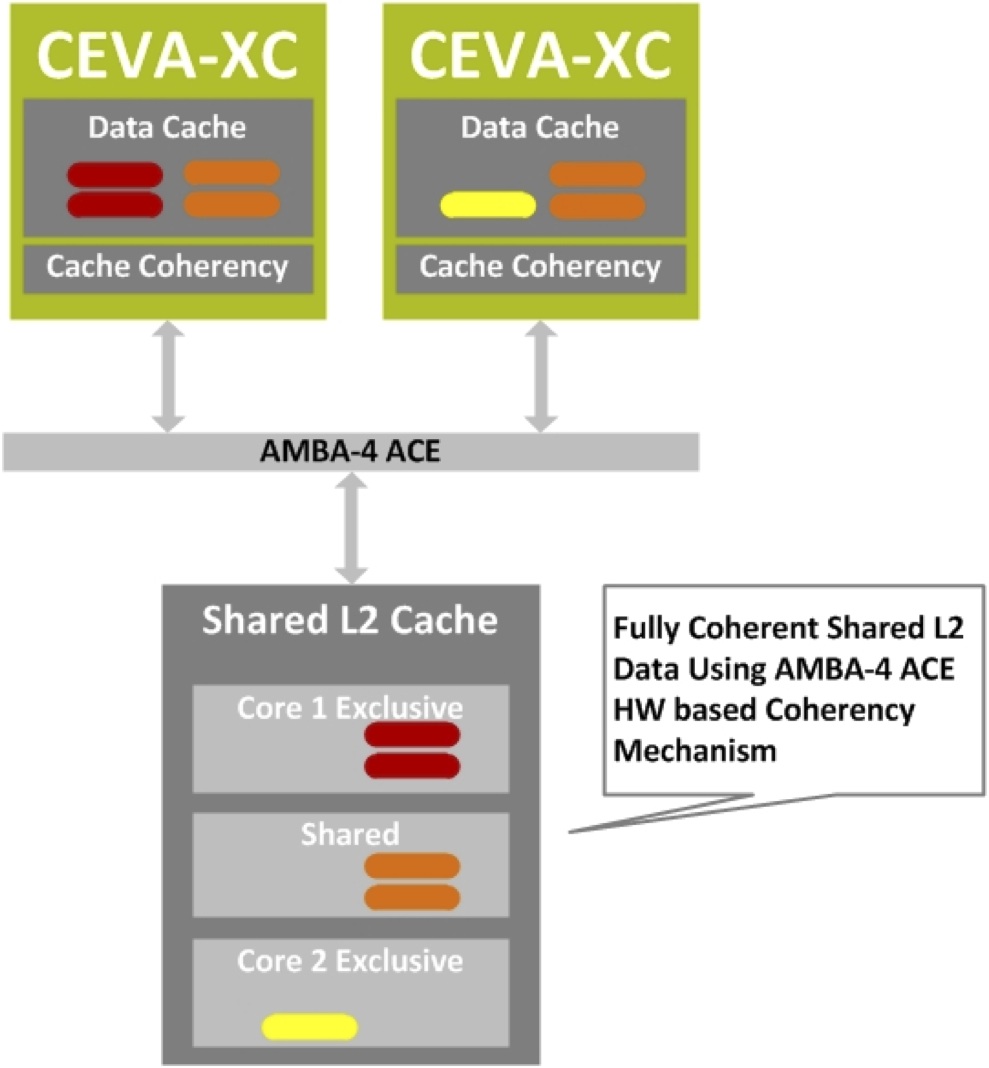
Figure 3. XC-4500 hardware-based cache coherency includes the flexibility to uniquely assign portions of the L2 data array to particular cores.
Even in the simplest single-core system configuration, the XC-4500's data traffic management support automatically assigns tasks to the queues of various TCEs and other hardware resources based on task priority and buffer status (Figure 4). And when multiple XC-4500s are in use in a homogeneous clustered fashion, shared system memory provides a similar (albeit higher level) dynamic scheduling capability at runtime. CEVA-Toolbox software development environment-supported task-oriented APIs abstract the particular silicon implementation. And assigning an array of data for a particular task to a specific core involves only passing a pointer, versus a performance- and power-sapping bulk data copy operation.
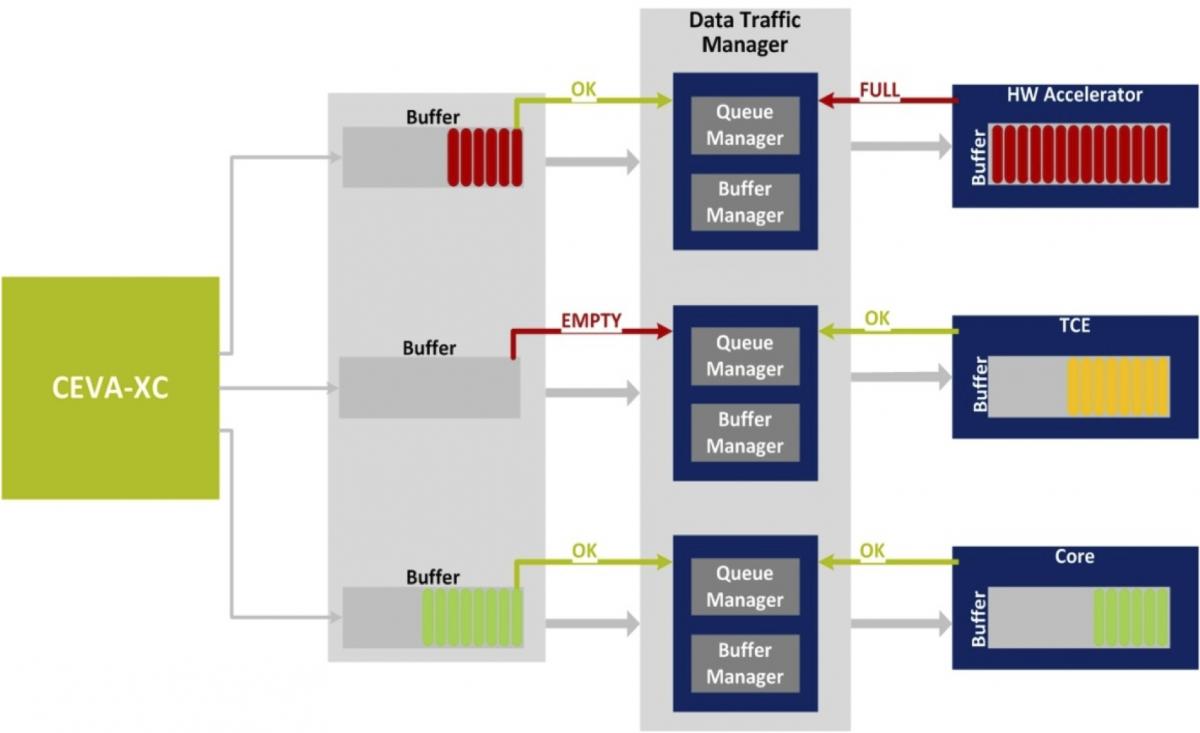
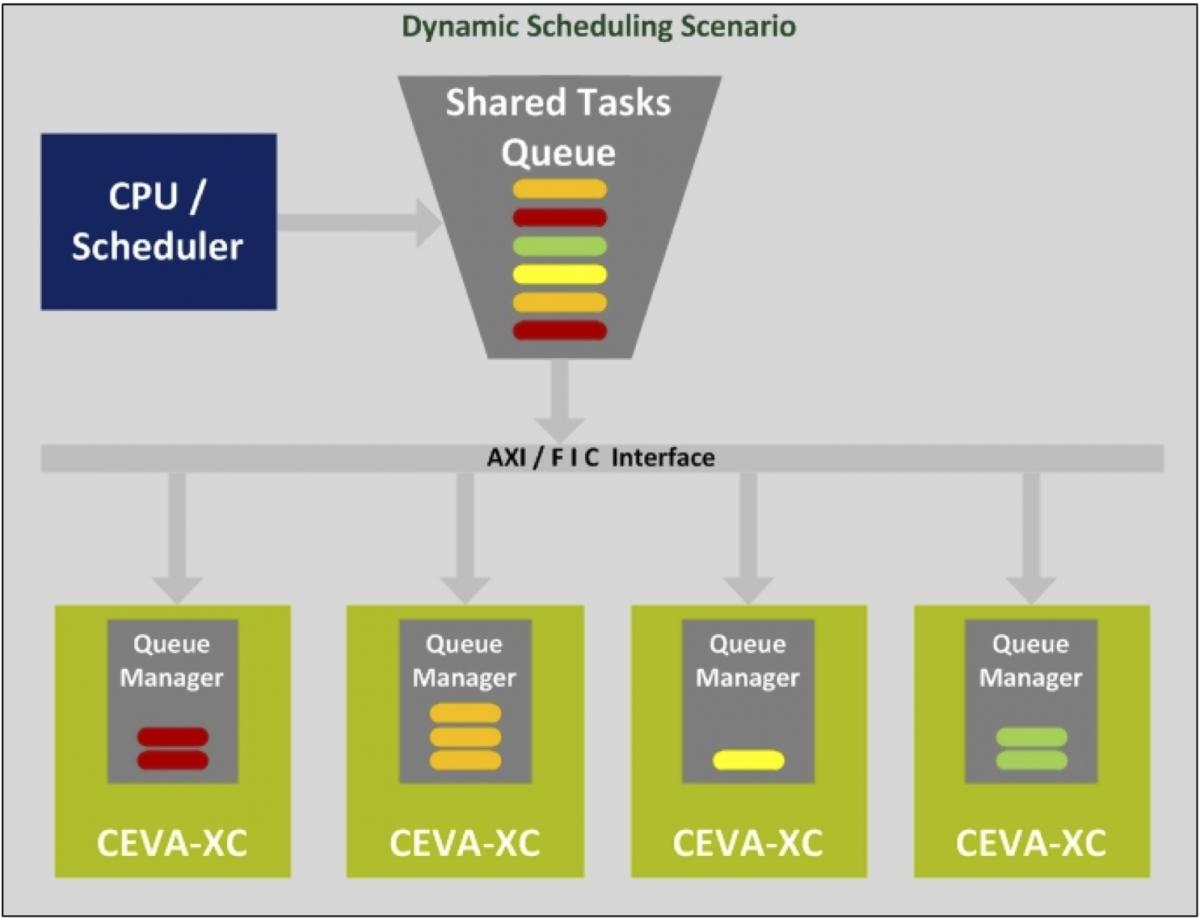
Figure 4. Built-in traffic management automatically assigns tasks to various on-core hardware resources based on priority and availability (top), while dynamic scheduling support implements conceptually similar capabilities at a multi-core higher level (bottom).
Speaking of power consumption, CEVA estimates that an XC-4500-based picocell SoC configuration capable of 2x2 MIMO LTE baseband processing will consume only 100 mW. More generally, on a 28 nm process foundation, an XC-4500 design will require between 2 and 4 mm2 of silicon area, depending on the single- or multi-core configuration, the number of TCEs included in it, and the amount of allocated memory. Communication libraries supplied by CEVA include HSPA+, TD-SCDMA, Wi-Fi and, new to CEVA-Toolbox, LTE and LTE-Advanced.
Only time will tell if the XC-4500's enhancements enable CEVA to expand beyond its historical handset roots and more broadly service the wireless industry with its DSPs. But early results are encouraging; the company reports that it's already secured one notable (albeit unnamed) licensee.
Add new comment