
Many high-performance DSP and general-purpose processors are equipped with SIMD single-instruction, multiple data) hardware and instructions. SIMD enables processors to execute a single instruction (say, an addition) on multiple independent sets of data in parallel, producing multiple independent results.
SIMD support has become increasingly common because it improves performance on many types of DSP-oriented applications (which tend to perform the same operations over and over again). But what if you’re implementing a DSP-oriented application on an embedded processor without SIMD support? Depending on the specifics of the application, the data, and the processor, it might make sense to emulate SIMD in software.
In this article, we'll give some examples of how to implement software-based SIMD, and quantify the processing speed-up you can achieve with this technique.
We'll also explain how to determine when "soft SIMD" is likely to be useful; unlike many other optimization techniques,soft SIMD is only useful for a relatively small range of applications and processors, and it imposes significant limitations on input operands. But in digital signal processing applications, where you're often trying to squeeze every last cycle out of a processor and you're willing to put in significant extra work to meet performance targets, it's a useful addition to your optimization toolkit. Here at BDTI we've used soft SIMD optimizations in a couple of demanding projects and it's proven to be worth the effort.
SIMD processors
In a processor with explicit SIMD support, one operation is executed on two (or more) operand sets to produce multiple outputs. This is often accomplished by having the processor treat registers as containing multiple data words; for example, a 32-bit register can be treated as containing two 16-bit data words, as illustrated in Figure 1. In this case, the processor automatically handles sign and carry propagation for each of the SIMD calculations. Most processors with explicit support for SIMD operations also provide instructions to allow the programmer to pack and unpack the registers with SIMD operands.
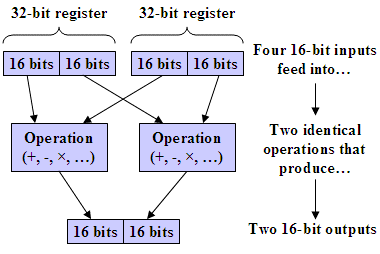
Figure 1. Diagram of SIMD (single instruction, multiple data) processing. SIMD performs the same operation simultaneously on multiple sets of operands under the control of a single instruction.
SIMD tends to be very effective at accelerating algorithms and applications that are highly parallel and repetitive, such as block FIR filtering or vector addition.As you’d expect, it’s not effective for processing that’s predominantly serial, as in control code, or when operands are scattered in memory and can't be easily packed and unpacked into the registers.
Try a softer approach?
If you’re implementing an algorithm that’s a good fit for SIMD but your processor doesn’t explicitly support SIMD, you might want to consider emulating SIMD in software to boost performance. You'll need to evaluate whether the application, data, and processor are good candidates for soft SIMD. In most cases it only makes sense if the processor has registers that are wide enough to hold at least four data operands; for example, if the processor has 32-bit registers and your data is 8 bits wide. In contrast, if your processor has 32-bit registers and you need 16-bit operands (for example), you’re less likely to find soft SIMD useful. That’s because some of the overhead of implementing soft SIMD is constant regardless of how many words you process in parallel.
The input operands must be amenable to fairly severe limiting—you'll often find that it's only useful if your operands can stay within, say, a 7- or 8-bit range. Soft SIMD is also best suited for operating on fairly large data sets, where the overhead can be amortized over many operations.
Video and imaging applications are often good candidates for soft SIMD because they use large data sets, execute the same operations repetitively, often use 8-bit data, and are frequently implemented on embedded processors that have relatively wide registers and no native SIMD support (like some ARM and MIPS cores).
Bashing the bits
In this section, we’ll provide a few examples of how soft SIMD can be implemented, including a video-oriented example implemented on an ARM core. We’ll focus on shift and addition/subtraction operations; other operations (such as MACs) can also be implemented using soft SIMD, but are significantly more complicated. Also note that there are usually multiple ways to implement soft SIMD; our goal is to provide examples that kick-start your thinking on the subject rather than to exhaustively cover every possible approach.The approach that provides the best results will depend on the processor, the application, and the data.
We’ll start with the case of a logical right shift. For illustrative purposes, we’ll assume that register A contains four equal-length operands (for example, register A is 32 bits wide and it contains four 8-bit operands). Once the data is packed into the register, you can use a standard "shift" instruction to shift the entire register (and thus the four operands within it) to the right.
Because this operation causes operands to shift across operand boundaries, it's necessary to create a mask to zero out the leading bit(s) of each shift result. The mask only has to be created once per shift amount, but the number of instructions required to create it can be fairly large. For this reason, using soft SIMD for logical shifts is generally only useful when the shift amount is constant or if the amount of data to shift (per shift value) is large.
Using pseudo C-language notation, the four operands in A can be simultaneously shifted by a variable shift amount as follows:
// generate mask before computationally-intensive loop
k=8*sizeof(sub-operand);
m=((2^s)-1)<<(k-s);
mask=m|m<<k|m<<(2*k)|m<<(3*k);
// computaionally-intensive loop using soft SIMD
{
// somewhere in this loop, perform a SIMD shift:
A=(A>>s) & ~mask;
}
So how much of a speed-up can soft SIMD shifts give you? If you're shifting four operands by a constant shift amount and the operands are already packed into a register, then you'll need just one shift and one and per four operands (rather than one shift per operand if you’re not using soft SIMD). Assuming that shifts and ands require the same number of instruction cycles, this approach translates into a 2X speedup in the inner loop (which doesn't count the overhead of mask generation and packing/unpacking operands).The overhead will vary based on the processor and on the arrangement of data in memory, but you're still likely to end up with a significant performance improvement.
Arithmetic left shifts are identical to logical left shifts. Arithmetic right shifts, however, are more complicated because you need to manage the signs of the operands. You can generate a sophisticated, data-dependent mask to do this, but it usually isn’t worth the effort—the overhead typically outweighs the benefit.
Soft-SIMD Addition
Soft SIMD can also be used for implementing addition. The exact implementation approach will vary depending on whether the operands are signed or unsigned; typically you’ll need to either limit the operands so that the additions won’t generate a carry, and/or define “guard bits” to ensure that carries aren’t propagated into adjacent operands. For example, if the addition operands are all unsigned, the register is 16 bits wide, and each operand is 8 bits, each addition must be limited to the [0…127]+[0…128] range. (Otherwise the carry propagation corrupts the results of an adjacent operand.) Once you’ve packed the operands into the registers and dealt with the carry issue, you simply add the full-width registers to generate multiple results.
An example of implementing soft SIMD additions is shown in Figure 2, where 16-bit registers are packed with two data operands each. Here, the operands are all negative, and are limited to 7 bits (including the sign bit). The eighth bit is used as a guard bit to avoid carry propagation in the result; all four input guard bits must be set to zero prior to the addition. The result range is limited to [-64(0x40)… -1(0x7F)] + [-64…0]. After the addition, the guard bit is set to 1 to represent the sign of the negative result.
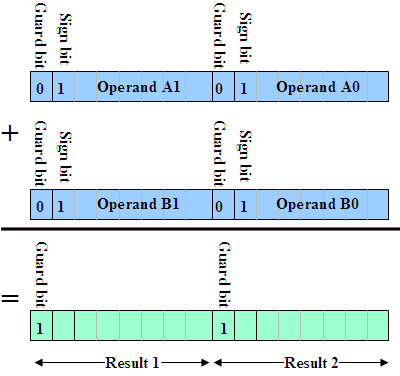
2. Using soft SIMD to perform two simultaneous additions of negative operands. There are two operands packed into each 16-bit register; each operand (A0, A1, B0, B1) must be limited to fit within seven bits (including the sign bit) to avoid carry propagation. The result guard bits are actually the sign bits.
Not all applications can tolerate the operand limiting required by this approach, but for those that can, soft-SIMD addition can provide a significant boost in performance, as shown in the following example.
Example: Soft-SIMD Addition on ARM core
One application for soft-SIMD addition is byte averaging, which is commonly used in image and video processing. Consider the following C code, which computes the pair-wise average of four byte-wide pairs of elements from vectors A and B by computing (A+B)/2:
*avg++ = (*a++ + *b++) >> 1;
*avg++ = (*a++ + *b++) >> 1;
*avg++ = (*a++ + *b++) >> 1;
*avg = (*a+ *b) >> 1;
LDRB r3,[r1],#1
LDRB r12,[r2],#1
ADD r3,r3,r12
LSR r3,r3,#1
STRB r3,[r0],#1
LDRB r3,[r1],#1
LDRB r12,[r2],#1
ADD r3,r3,r12
LSR r3,r3,#1
STRB r3,[r0],#1
LDRB r3,[r1],#1
LDRB r12,[r2],#1
ADD r3,r3,r12
LSR r3,r3,#1
STRB r3,[r0],#1
LDRB r1,[r1,#0]
LDRB r2,[r2,#0]
ADD r1,r1,r2
LSR r1,r1,#1
STRB r1,[r0,#0]
BX lr
If you re-work the code to implement this functionality using soft SIMD, however, the same inner-loop processing can take as few as 9 instructions, as shown in the code below.
The trick to using soft SIMD in this example is to recognize that you can recast the computation of (A+B) to avoid generating 9-bit intermediate results (which would overflow into adjacent operands).
To do this you halve the inputs, changing (A+B)/2 into (A/2)+(B/2). These two expressions are obviously not equivalent; by truncating the input operands before summation, you have lost the least-significant bits of each operand. The truncated bits (if non-zero) could havelead to a carry propagation in the final result. To compensate for the loss, calculate the carry bits (if present) before truncating the inputs, and then add them back into the final result.
The resulting ARM assembly code looks like this:
;r0 = pointer to output array
;r1 = pointer to input vector A
;r2 = pointer to input vector B
;r3 = 'mask' = 0x01010101
LDR r4, [r1, #0] ;Load four bytes (A)
LDR r5, [r2, #0] ;Load four bytes (B)
AND r6, r4, r3 ;Isolate least significant
;bits of the elements of A
AND r7, r6, r5 ;AND with least significant
;bits of elements of B
;r7 now contains valid data in
;positions [24], [16],
;[8], and [0]; a '1' implies a
;'low-order-carry' into the
;result; a '0' implies no carry
BIC r8, r4, r3 ;mask out LSBs of elements of A
BIC r9, r5, r3 ;mask out LSBs of elements of B
;These two masking operations
;assure no bits cross byte
;boundaries when we halve the
;input operands
ADD r10, r7, r8, lsr #1 ; low-order carry + A/2
ADD r11, r10, r9, lsr #1 ; += B/2
STR r11, [r0, #0] ; store 4 bytes
Clearly this code is both harder to write and harder to read than the original version—but depending on the application, the resulting performance improvement may be worth the additional coding, debugging, and maintenance effort.
Subtraction
Implementing soft-SIMD subtraction is similar to addition, but it only works if the operands are of the same sign. For same-sign subtraction, the primary difference between soft-SIMD addition and subtraction is that in the subtraction, all of the guard bits in the first argument register must be set to a value of one (rather than zero).
Extending hardware SIMD
Soft SIMD is sometimes also useful for extending the capabilities ofprocessors that have hardware support for SIMD. Some DSP processors,for example, have explicit support for 16-bit SIMD operations, but not for 8-bit operations—which can then be implemented using soft SIMD. In addition, some processors can execute multiple instructions in parallel, but only a subset of these instructions can be SIMDinstructions. In such processors, soft SIMD can be used to augment the native SIMD capabilities of the processor.
Use under pressure
Soft SIMD places significant limitations on operands, and it's challenging to implement. It's really only useful for a limited range of applications and processors. So why is it worth the hassle? Because in those few cases where it's applicable, it can help you meet performance targets you would otherwise miss, and it may be less painful than the alternatives. If you're coming up short on MIPS and you’re faced with the prospect of switching processors or cutting out features, soft SIMD can start to look pretty good.
Add new comment